Control Flow Overview
Control Flow is a perfect solution when you need to perform different data integration tasks in a specific order or depending on the specific conditions. It allows you to perform pre- and post-integration actions and even set up some automatic error processing logic within your integration.
Convenient Designer
Control Flow is configured in an easy-to-use and no-coding visual designer that makes configuration of even complex scenarios simple enough and allows both professionals and business users to design their control flows.
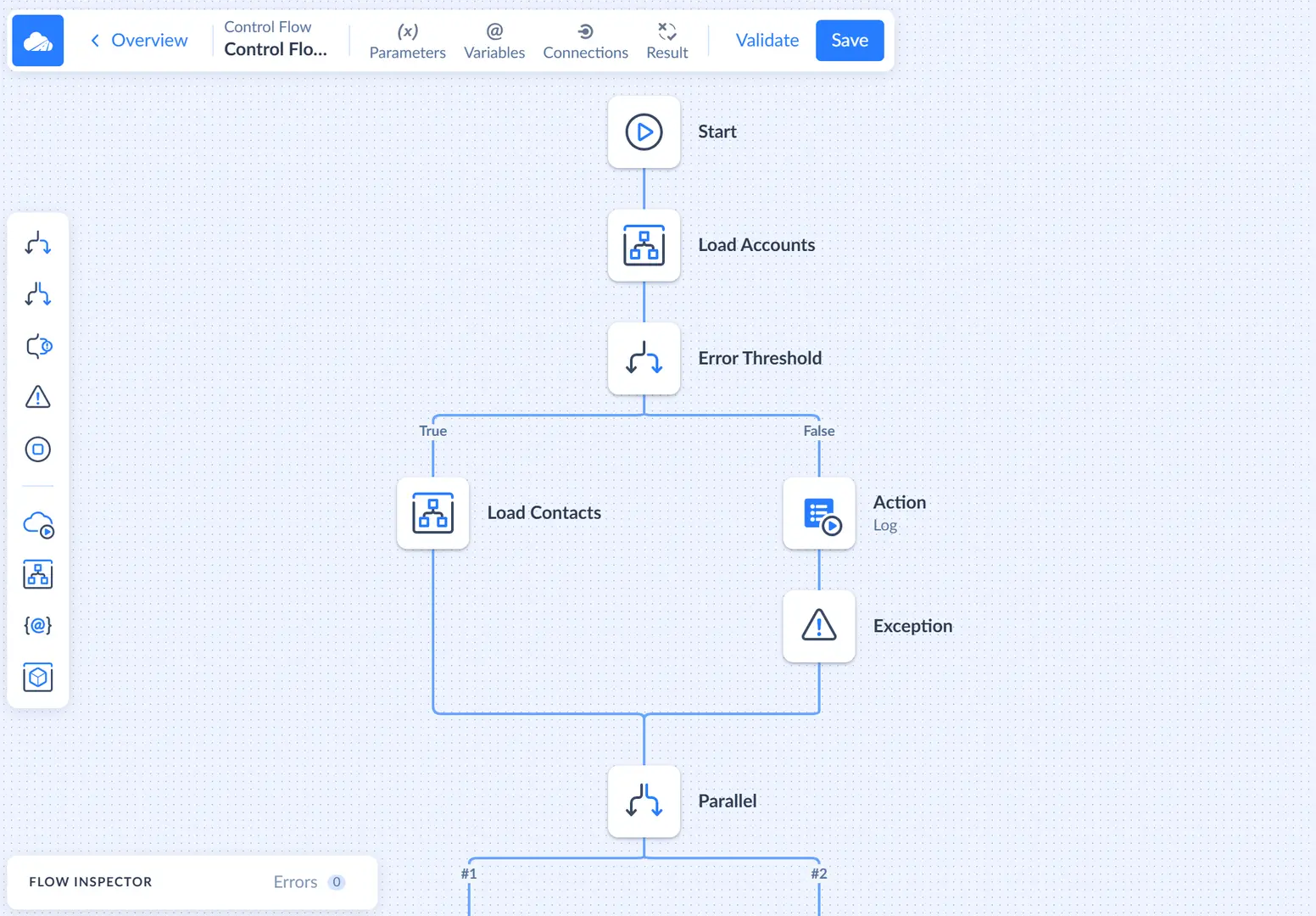
You design your control flow on a diagram which displays components and branches that connect them. The execution goes from the Start component to the Stop component (from top to bottom), and it goes via the diagram branches and components on them.
When you create a diagram, it has two components - Start and Stop, and a branch connecting them. You can add more components to the diagram and place them on any branch between any two components. See more about setting up a control flow in the How to Design or Edit Control Flow topic.
Control Flow Components
Control Flow components can be divided into two groups: control blocks and tasks. Control blocks control the execution, creating branches and redirecting execution between them depending on some conditions.
The second group - tasks, do not affect the control flow execution directly, but they interact with data sources or set variables. They can run other integrations, data flows, perform other actions, etc.
See more about specific Control Flow components and their settings in the Components topic.
What You Can Achieve with Control Flow
Running Integrations in Specific Order
One of the easiest scenarios that can be implemented with Control Flow is running several different integrations in a specific order, one after another. For example, you may need to load some data from SQL to Salesforce and then update some different data in SQL Server from Salesforce.
Without the Control Flow you could only schedule integrations to run one later that another, but this is inconvenient, because you cannot always know how much data must be loaded and how much time it would take. But with Control Flow you can easily run the next integration right after the current one finishes its work. Just add Execute Integration components to a branch one after another. Or you can add Data Flow components in a sequence and perform a sequence of Data Flows.
Perform Pre- and Post-Integration Tasks
Another scenario for Control Flow is when you need to do something before or after running the integration or both. For example, you load data to a database, and need to create database table for it in advance. Or you loaded certain records from source to target and want to delete them in source afterwards.
In this case you can use the Action components to perform these pre- and post-integration tasks, and Execute Integration or Data Flow component to perform the actual data loading.
More Complex Scenarios
Control Flow offers great flexibility and can be used for more complex cases than mentioned. It allows you to add error processing logics in case of integration level errors, direct execution into different branches depending on the specified conditions, etc.
You can set variables within the control flow directly or within its data flows, and then implement conditional logics and perform different actions depending on their value.