Data Flow Overview
Data flow allows you to integrate multiple data sources and enables advanced data transformations while loading data. It can be used in the scenarios when data replication or import is not enough:
- when you need to load data into multiple sources at once
- when you need complex, multistage transformations, like lookup by an expression
- when you need to obtain data from one data source, enrich them with data from another one and finally load into the third one
In Skyvia, Data Flow processes records in batches. A batch of the records is read from a source, then it is moved to the next component via the link and is processed there while the source obtains the next batch, then is passed to the next component, and so on. Batch size is not a constant, data flow components may split a batch into several smaller batches sent to different outputs.
Easy-to-Use Designer
Despite being intended for complex integration scenarios, Data Flow is an easy-to-use no-coding tool that can be used both by business users and IT professionals.
Skyvia allows you to build and edit data flows on diagrams. Basically, at the beginning, diagram is a blank canvas, which you fill in with components to arrange the entire process of data movement visually. You drag components onto the diagram, connect them with links, make data transformations in-between and pass changed or split data to the final destination.
You can easily copy and paste, edit, or delete components out of the diagram anytime you need.
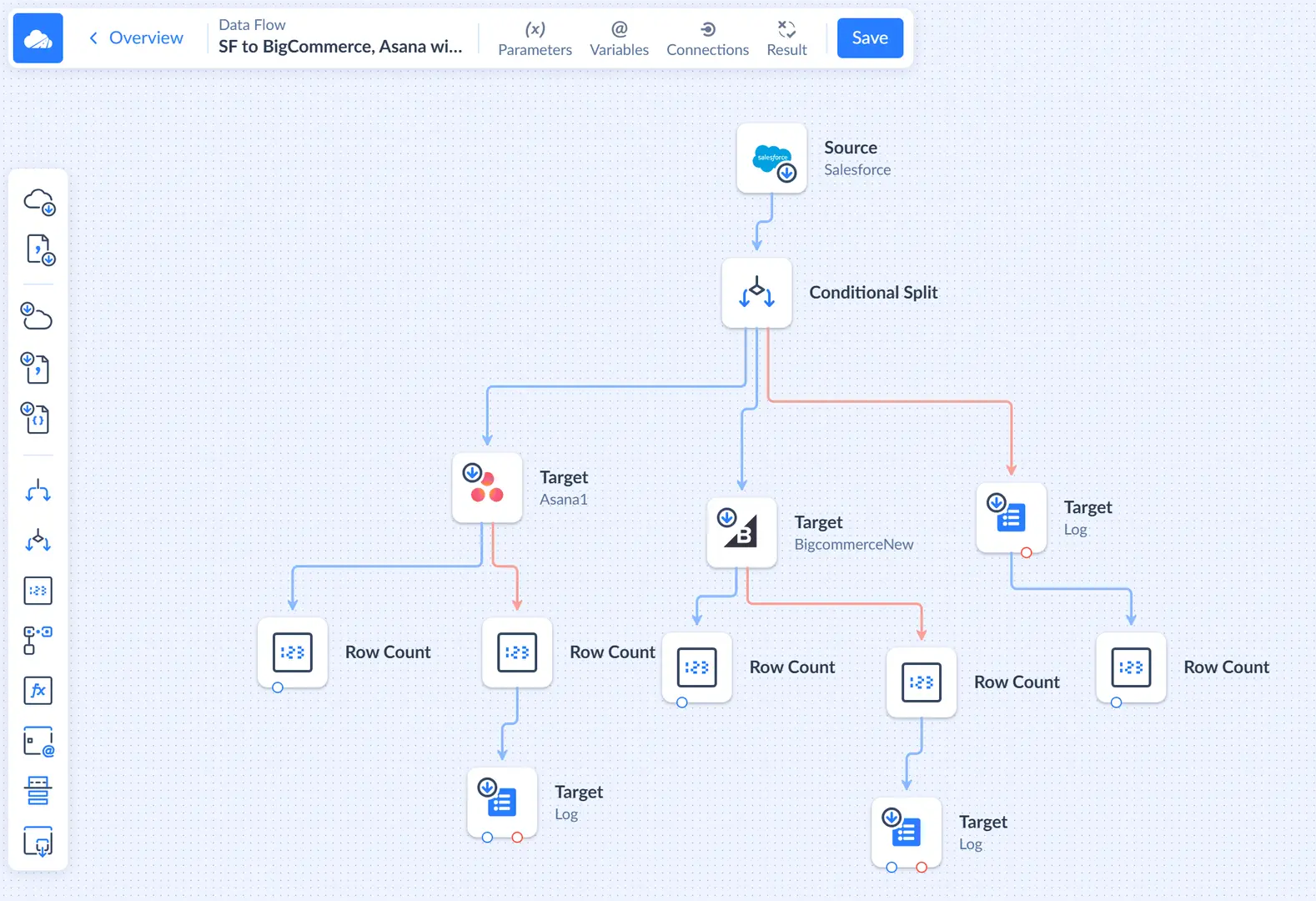
Types of Data Flow Components
Data Flow components can be divided into three categories: sources, targets and transformation components.
- Sources. Source is a component, which represents an action of data extraction from external data sources and bringing them into the flow. Skyvia supports data extraction from a variety of source connectors, among them databases and cloud apps, including Salesforce, SQL Server, etc.
- Transformations. Transformation components modify the data, flowing through them, split flows of records into multiple outputs, or modify data flow variables.
- Destinations. Destinations accept data and store them. Skyvia supports loading data to lots of target connectors among which — various cloud apps and databases, as well as files - downloadable manually or placed to file storage services. You may also use outputs of a target component to process and send the successfully stored or failed records further to another destination, applying additional modifications if needed.
Inputs, Outputs and Links
Components have their inputs and outputs, which are data entry and exit points. You can connect outputs of one component to inputs of other components, creating a link. Links show the direction of data movement between components, and are displayed as arrows on the diagram.
A component usually has one input (except source - source component has only output) and one or more outputs. Outputs can be of two kinds - regular outputs and error outputs.
Records that have been successfully processed go to regular outputs. A component may have one or more regular outputs. Records that have failed to be processed go to the error output with error message added. A component can have either one error output, or no error outputs, if this component cannot fail processing a record at all. Links, going from regular outputs (regular links) are displayed as blue arrows, and links, going from error outputs are displayed as red arrows.

Actions
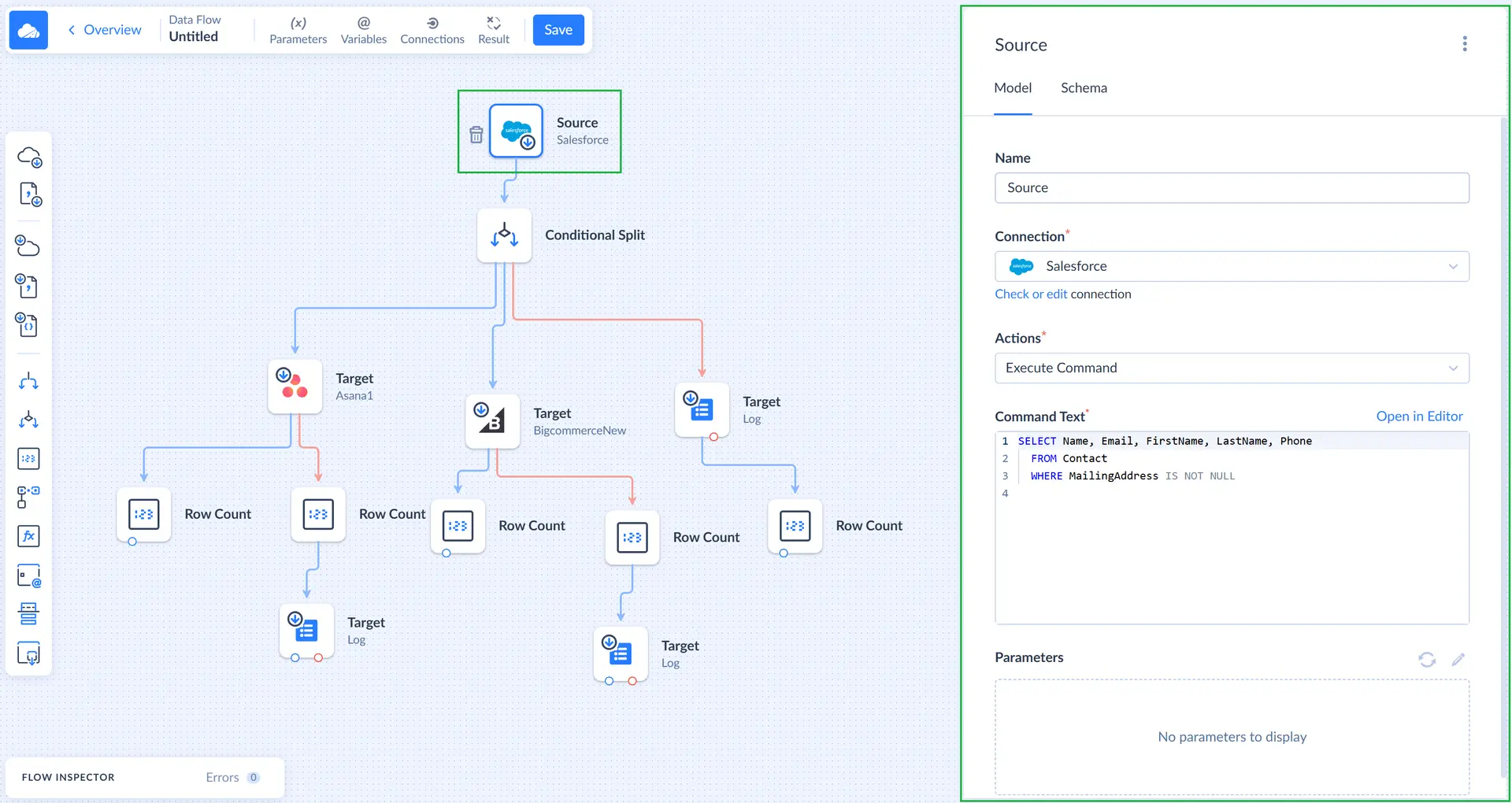
Action is an operation performed by a component to obtain data from the data source or store them. The following components work with data sources: sources, targets and lookups (transformation component). For these components, you need to configure actions. Each type of data flow components has its own set of available actions.
Each kind of components has its own actions available, and the list of these actions also depends on the data source. For example, the Target Connector component usually has Insert, Update, Delete, and Execute Command. If a Salesforce connection is selected, there is also Upsert action available.
Integration Variables and Parameters
Integration parameters allow storing certain values between data flow runs and use them in the next runs. For example, your data flow loads records from a data source with autogenerated numeric Ids, and new records are assigned Ids greater that any existing Ids. You have loaded all the records, existing at the moment, and want next run to load only new records. In this case, you may store a max Id from loaded records in a parameter with a Value component and next time load only records with greater Ids.
For each integration parameter, a variable is automatically created. This variable is assigned a value from a parameter when the integration execution is started. When the integration execution is finished, the variable value is automatically saved to a parameter.
You can also create additional variables, whose values are not stored in the parameters between integration runs, and are available only within the integration run. You can use them, for example, to count processed records and output results to the data flow log.
Data Flow Tutorials
You can read the following tutorial, describing creation of a simple data flow and explaining it in details: Loading New Records from Autoincrement Table. This tutorial shows how to load new records from an autoincrement table.
Another tutorial Updating Existing Records and Inserting New Ones describes how to check the target table if a record is already present there and avoid creating duplicates when loading data in a data flow.